awk和流编辑器sed在工作原理和用法上有很多类似之处,它们都是检查输入数据中的行是否匹配指定的模式,如果匹配成功就对匹配的行执行相应的操作,重复这个过程直到所有的输入数据都被处理完,因此awk和sed都是面向数据流的工具。
awk执行的操作action要写在模式后面的花括号{}中,而sed是直接接在模式后
比对:
- sed通常用来提取一整行,提取一行中的某个字段需要使用后向引用;
- awk通常用于提取行中的某个字段,也可提取一整行;
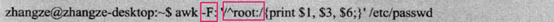
注意:上面的花括号中各个参数之间的逗号不是必要的,使用逗号在输出时各个字段之间会增加个空格,增加可读性
格式:
awk [options] -f progfile [--] file ... #将程序语句写入到文件中,通过-f调用
awk [options] [--] 'program' file ... #直接在命令行中写出程序,更常用
可以看出awk同样可以同时处理多个文件
有前面可知,三剑客grep、sed、awk都可以用来同时处理多个文件
awk的程序('program'或progfile)中包含了一系列的规则,在每一个规则中都指定了一个要查找的模式,以及对匹配模式的行所执行的操作。
awk程序中的规则格式如下:

pattern是一个正则表达式,就是我们要匹配的模式(匹配流入的文本的行),
而花括号{}中的actions是对匹配到的行数据所执行的操作,它既可以是一个命令,也可以是多个命令,每一个命令用分号结束。
如果把其中的匹配模式省略(即/pattern/),awk会对输入数据的每一行都会按行执行actions所指定的操作(类似sed)
awk的强大之处在于它会自动把输入的行数据分隔成若干个字段。所谓的字段就是被指定的分隔字符分隔后的一段段字符串,如果没有修改,awk默认的分隔字符为空格。
awk读入一行数据以后,会根据所指定的分隔字符把行数据分解为若干个字段,然后把每-个字段保存在以数字命名的变量中,如第一个字段被保存在变量1($1)中,第二个字段被保存在变量2($2)中…最后一个字段保存在$NR中,而整行数据被保存在变量0($0)中。
如果希望在awk程序中引用某个字段的值,只要使用字符$引用相应的变量即可,如第一个字段的值为$1。
如果在花括号中没有为print命令添加参数指定要输出的字段(即只有print指令,没有变量$1,$2,$3等),它会默认打印整个输入行,就像指定了参数$0一样
print命令不带参数和指定参数$0得到的结果是相同的,都是原封不动地打印整行数据。
除了使用print命令打印信息以外,还可以使用printf命令
printf命令默认不会在字符串结尾处、添加换行符,因此需要在字符串的最后手动添加\n
不管是使用print进行输出(自动在行尾添加换行),还是使用printf(不会自动在行尾添加换行)都支持各种格式化的转义字符(\n、\t、\v、\b等).
如果是输出普通字符,最好使用双引号引起来(除了$0,$1,$2…$NR外其余全部看作普通字符)
awk -F: '/root/{print "Username: " $1 "\t" "UID: " $3 }' /etc/passwd
通过标识符BEGIN可以在处理数据以前执行一些初始化操作,可用来输出表格的标题,自定义变量等。
awk的整个结构如下:
awk ‘BEGIN { } [/pattern/]{ 主循环} END{ }’ FILE1,FILE2…
如果awk的程序较长,通过命令行的方式执行程序不是很方便,可以先将awk程序写入到文件中,然后使用awk的-f选项传递给awk

把awk程序写在文件中还有一个好处,就是可以添加注释(#),方便以后对程序的分析和维护,位于#和下一行之间的内容视为注释
在第一行数据被读入以后主循环就开始执行,并且输入数据中存在多少行,主循环就会被重复执行多少次,一直到处理完所有的数据为止,此时主循环就会退出。
除了主循环以外,awk的程序中还有另外两个特殊的阶段:
一是在数据被读取之前(BEGIN { }) #主循环开始以前执行一些初始化操作
二是在所有的数据都处理完以后(END {}) #主循环终止以后执行一些收尾工作
/pattern/:对读入的行进行匹配
awk中匹配时有多种形式:
1、NF 使用字段个数匹配(默认是每行的字段数)
2、NR 使用记录个数匹配(默认是行数),使用较多
3、FS 使用字段分隔符匹配(字段分隔符,默认是空格)
4、NS 使用记录分隔符匹配(记录分隔符,默认是换行\n)
5、/pattern/ 正则表达式匹配,正则匹配时,必须放在/regex/内 行匹配;如果pattern中包含/字符,则需要使用反斜线\转义
6、$1~/pattern/ 该行的第一个字段如果正则匹配到pattern,则匹配该行
7、布尔表达式(即逻辑表达式)匹配,仅当布尔表达式为真时,才会执行后面的action
awk -F "[ /]+" '$2~/^80$/{print $0}' /etc/services
逻辑表达式expression中的操作符:


可使用逻辑与&&和逻辑或 || 把多个表达式连接在一起构成更复杂的表达式

当在awk程序中指定了多个规则时:
默认awk读入的每一行数据都会所有规则独立处理(类似sed的-e多模式)
(awk -F: '$7=="/sbin/nologin"{print $1}; $3>500{print $1}' /etc/passwd 两个条件都满足,会被打印两次,每行被独立执行),有时这种情况是我们所不希望看到的。
例如:
处理/etc/passwd文件的awk程序中有两个规则,一个规则是打印所有使用bash shell的用户,另一个规则是打印所有UID大于等于1000的用户,如果一个用户同时满足两个条件,那么它就会被打印两次,如何解决?(我们要的效果是只要符合其中一条规则即打印出来)
两种方式解决:
其中一种方法,就是通过逻辑操作符或||把两个规则合并为一个规则
awk -F: ‘($3>1000)||($7==”/bin/bash”){print $0}’ /etc/passwd
#两个条件之间使用||连接
另一种方式,使用next命令:
awk -F: '$7=="/sbin/nologin"{print $1;next;} $3>500{print $1}' /etc/passwd #两个条件之间使用空格分隔

注意:
执行next命令,它的作用是结束当前行的处理(即如果该规则条件满足,跳过后面的其它所有规则),让awk读取下一行数据,接下来读取第二行数据,从第一条规则开始重复整个过程,有点类似C中的continue。
next前必须有分号(两个指令间隔),其后的分号可有可无
当awk程序中存在多个规则的过程:
awk在读取-行数据以后,会把这行数据与程序中的第一个规则进行模式匹配(或者判断表达式),如果匹配成功就执行相应的操作;
然后这行数据(原本的,不是经第一个规则处理后的)会继续与第二个规则进行模式匹配(或者判断表达式),根据成功与否来决定是否执行相应的命令,以此类推,直到这行数据经历了所有规则的匹配,然后awk会读取下一行数据并用同样的方式进行操作。
因此,如果一行数据同时满足了两个规则的条件,则这两个规则所包含的命令都会被执行,相反,如果没有一个规则能够匹配这行数据,也就没有一个规则的命令会被执行。
awk中的printf输出时,共有3种形式:
printf(“%-12s%8s”),$8,$7
printf “%-12s%8s”,$8,$7
pinntf(“%-12s%8s”,$8,$7) #这种与C中完全相同
C中的所有格式控制均可用在这里
awk脚本
要想创建awk脚本,只要在awk程序文件的头部添加如下一行:

同时为这个文件添加上可执行权限,就可以像执行普通Shell脚本一样执行awk程序了。这里添加的这一行与在Shell脚本中添加#!/bin/bash的意思是一样的,都是告诉系统应该使用哪个程序来解释当前的程序文件。使用bash执行脚本文件时不需要指定额外的选项,但是使用awk执行程序文件时需要使用选项-f,因此这里不仅要写明awk的程序路径,还要添加选项-f。



由于awk脚本本身只能处理数据,所以还需要提供一个数据源。在运行时,通过管道把命令ls -l的输出传递到awk程序的标准输入中,此时在管道字符|的后面可以直接输入脚本的完整路径 ./reverse_ls_output.awk

awk中的变量
AWK中的变量有内置变量和自定义变量之分
awk语言中的变量与Shell脚本中的变量很像,在使用前不用事先声明,直接使用即可,并且变量默认会被初始化为0或一个空的字符串。
由于awk语言是一个弱类型的语言,所以变量是没有类型的,同一个变量既可以保存字符串,也可以保存数值,不需要类型转换。
如果对一个已经赋予字符串值的变量进行算术运算,第一次运算时,该变量将会被赋值为0;
内建变量
FILENAME [awk读取多个文件时],显示当前读取的文件的名称,
NR 当前处理的是第几个记录,默认是第几行,[若有多个文件],记录数累加
FNR [awk读取多个文件时],读取新文件时,FNR为新文件中已读取的行数
注意:NR和FNR的区别
NF 当前行字段的个数
FS 输入行的字段分隔符,默认为空格,也可使用选项-F设定
RS 输入时的记录的分隔符(即输入数据的断行符),默认换行符
OFS 输出时的字段分隔符,默认空格
ORS 输出时的记录的分隔符(即输出数据的断行符),默认换行符
在awk中打印这些内建变量的值时,一定不要带$符号,如果带有$就会打印匹配行对应字段的内容
一个记录含有多少行是由记录分隔符(RS)决定的(默认RS是换行符,一行就是一个记录)
一行中含有多少个字段是由字段分隔符(FS)决定的(默认FS是空格)
FS和RS支持正则表达式
指定FS时需要注意:
1、 可以使用-F选型替代FS变量
2、 如果同时指定多个不同的分隔符,使用 -F “[ :]+” 这里就同时使用了空格和冒号:作为分隔符,+表示1或多个空格,或,1或多个冒号:




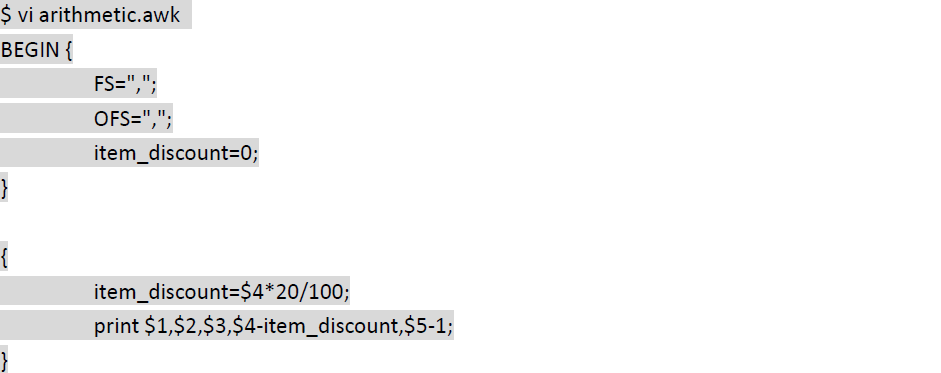
字符串操作:

赋值操作:

比较操作:

